
The fight to own web agent identity
Cloudflare, Anchor Browser, Browserbase and others aim to set the standard for who an agent really is


Cloudflare just announced a partnership with Anchor Browser, Browserbase, Block, and OpenAI to build identity for AI agents on the web. They define cryptographic “passports” that will identify “legit” agents from spammy bots.
It’s absolutely the case that we need better ways to identify agents, but not just because we need to throttle bad acting bots. Merchants / services on the internet will also need to prioritize important agents vs less important agents for service, route them to specific areas of the network optimized to handle their batched, high volume traffic, and need some level of tracking.
What’s interesting, is that it became clear a few weeks ago that we absolutely do not have the infrastructure to do any of this today.
Some quick context from recent events
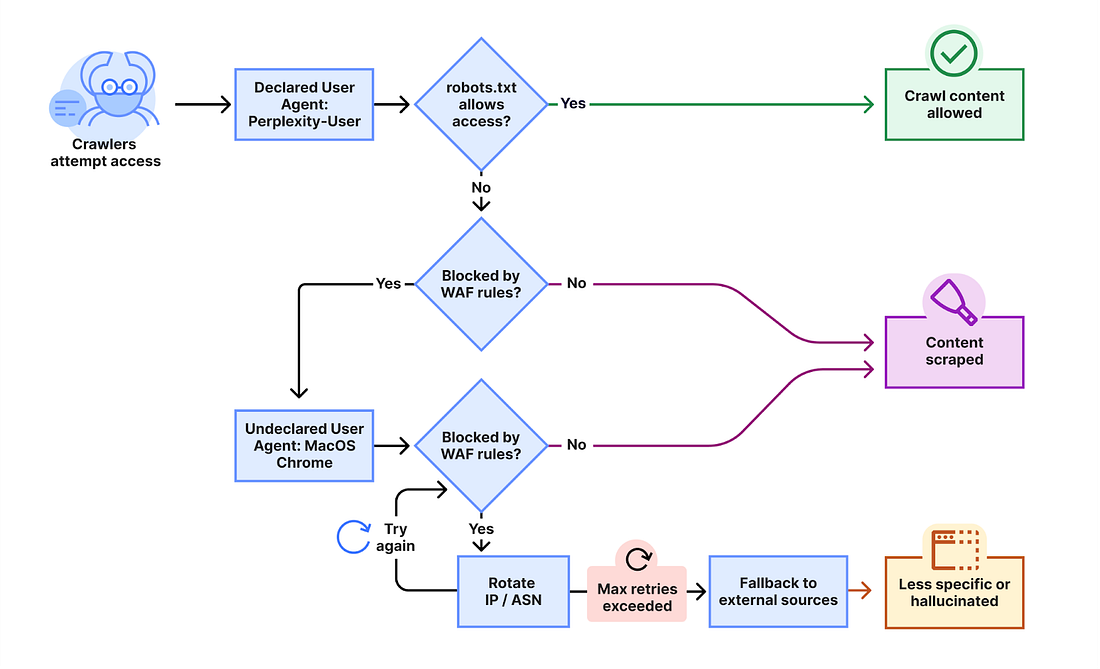
Three weeks ago, Cloudflare published a hit piece against Perplexity claiming that Perplexity’s scraping bot was not obeying robots.txt. They went further, and showed that even when Perplexity is blocked by a site’s WAF, it leverages stealthy, browser-based scraping obscured through residential IPs to avoid detection (see the above image depicting this architecture). Cloudflare cited 3-6M daily requests from a stealth scraper built on top of Browserbase.

Perplexity fired back immediately and pointed out that only ~1% of those “stealth” requests are from Perplexity’s specialized, browser based bot that is used for complex user requests. In fact, 99% of those requests are actually from Browserbase’s hosted offering covering a wide range of customers, and are not actually Perplexity.
They also highlighted the distinction of a scraping bot, which may be scraping data for storage & training vs. a user-generated agent that is accessing a resource on behalf of the user for a specific request.
Their point: Cloudflare does not have the technical sophistication to be able to differentiate between which agents are Perplexity vs other agent developers built on similar infrastructure. Furthermore, they lack the granularity of data to understand an agent or scraper’s intent.
Why It Matters
If perplexity is right (which it seems like they may be), this is concerning. Cloudflare is one of the central guardians of the internet and they do have a major role to play in ensuring that agents responsibly access resources on the internet. Agents consume compute resources, content, and potentially human capital at the sites, merchants, & services they interact with.
Some sort of identification system would be helpful, and likely additive to the agent ecosystem, and not just for merchants. Consumers are frustrated when their well-meaning, human-initiated agent is incorrectly blocked by a website’s firewall.
This is precisely what Cloudflare, Anchor Browser, Browserbase, and others are attempting to solve with their Web Bot Auth.
Each agent presents a cryptographic credential that identifies it to whatever resource it is attempting to interact with
Sites can verify the signature and decide whether to let it through
Websites can tie an agent back to the known issuer (and ensure some accountability)
Theoretically, this should mean that well-meaning agents are successfully routed & accepted, while suspicious ones get throttled or blocked.
Unsurprisingly, House YC and House A16z immediately battled it out on twitter on the merits of this standard.
I am cautiously optimistic.
It’s obvious that Cloudflare is wildly incentivized to define a standard on their own terms. And to that end, they need browser infrastructure companies like Anchor Browser & Browserbase to do so effectively.
The atomic unit of an agent is an “LLM + a tool”. By chaining that unit together, you can accomplish literally anything. Cloudflare & the browser infra companies aim to be the best generalized tool (a “Swiss Army knife” of sorts) - Cloudflare brings the tool itself and browser infra companies bring the skills + functionality to operate it.
And I expect many developers will find it to be extremely helpful in the near-term. The operative question that Gary and others raise, is what happens in the long-term if Cloudflare starts to tilt the ecosystem in their favor, and perhaps, to the disadvantage to other general tool providers.
Here, I am also not overwhelmingly worried. Let’s consider two examples:
SSL/TLS (the optimistic view) The early web struggled with trust. You had no idea if the site you were on was actually who it claimed to be. Netscape, the IETF, and a set of certificate authorities created SSL (and later, TLS) as a neutral, open standard. Any website could get a certificate from a recognized certificate authority, and browsers enforced the standard by warning users when a site wasn’t secure. Governance came from RFCs and open standards bodies, not a single corporation. SSL / TLS became the universal trust layer that made e-commerce and online banking possible. If Web Bot Auth follows this path, it could be the neutral protocol that makes the agentic web operable.
Google Search (an equally optimistic view, but with a winner). In the 2000s, as the internet became the primary front door for all content and businesses, Google became the de facto standard for finding information. But unlike SSL/TLS, there was no open protocol or shared governance. Google wrote the rules through Webmaster Guidelines (now Google Search Essentials) and enforced them via its ranking algorithm. Publishers who didn’t comply were dropped in the rankings and subsequently watched their website revenue plummet. Publishers “had to comply”, but because there was upside for them!
But here’s the thing: Google winning search didn’t mean a bad outcome for merchants OR consumers. In fact, quite the opposite. 36% of all e-commerce originates from Google, which has facilitated the creation & growth of millions of businesses. Merchants and consumers thrived under Google (all while “the competition was a click away”) and I don’t see any reason that agents and merchants (or data providers, service providers, etc.) can’t thrive under a theoretical Cloudflare reign.
Just because there is a winner, doesn’t mean that everyone else loses.
There will be other entrants, as the upside is significant for whoever wins out here. Perhaps the biggest question is, where on earth is Google in all of this?